Wooseok SeoHi! I am a 1st year Graduate student at Yonsei University, and a visiting researcher at PILAB, Seoul National University. I am fortunate to be advised by Prof. Youngjae Yu. My main research interest is in pushing the boundaries of foundational models through better evaluation frameworks or effective post-training . Recently, I am interested in:
I am also interested in leveraging models to evaluate or improve other models, or utilizing them to augment human capabilities. I am always open to research collaborations or grabbing a cup of coffee! Please reach me via email to have a chat 🤗 |

|
News |
| 2025.10 I am attending COLM 2025! I will be at Montreal from 10/5 to 10/11, so please reach out to have a chat ☕ |
2025.09
I will be joining
 as a Research Intern, working on foundational language models!
as a Research Intern, working on foundational language models!
|
| 2025.07 One paper on studying fact verifiers is accepted at COLM 2025! |
| 2025.06 One paper on video diffusion distillation via preference learning is accepted at ICCV 2025! |
Research |
|
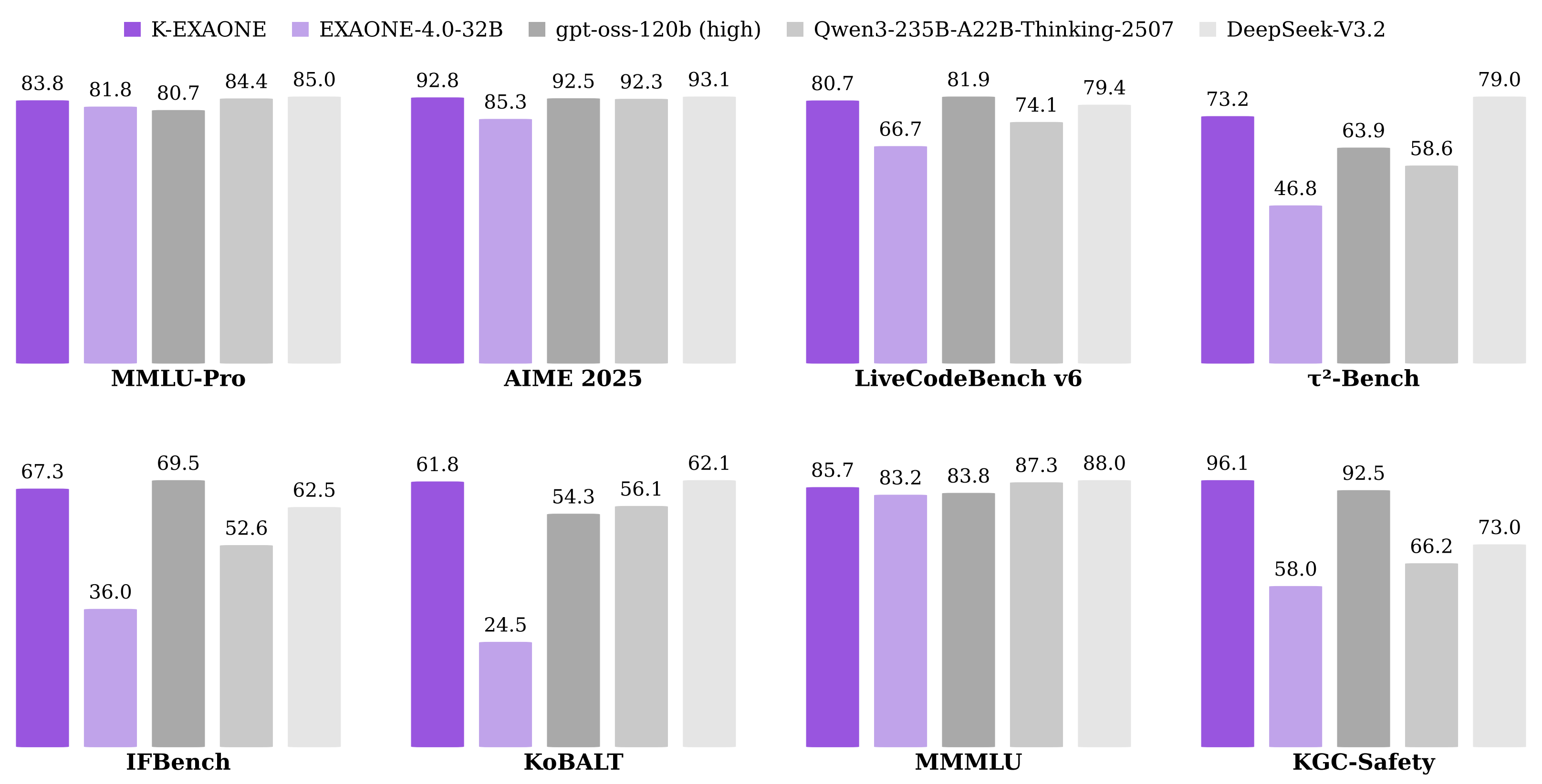
K-EXAONE Technical ReportLG AI Research Technical Report, 2026 We present K-EXAONE-236B-A23B, the best model in Korea. I contribute as a member of the post-training team, specifically working on synthetic data for reasoning. arxiv / code |
|
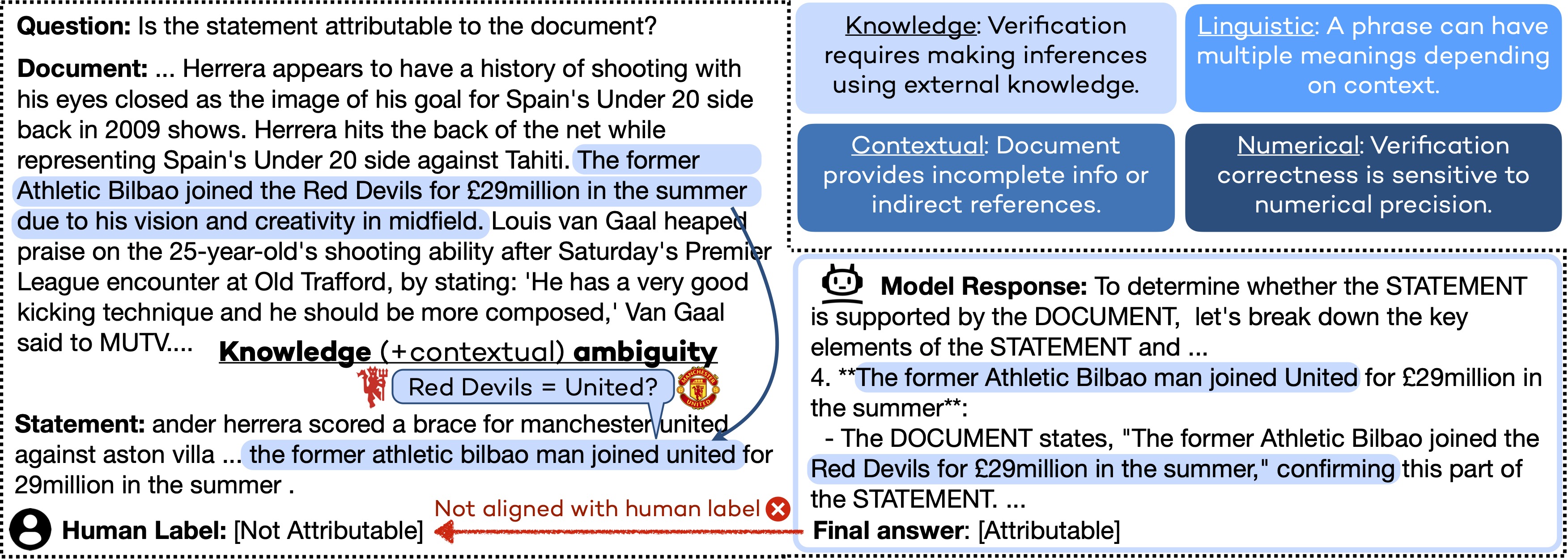
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact VerifiersWooseok Seo*, Seungju Han*, Jaehun Jung, Benjamin Newman, Seungwon Lim, Seungbeen Lee, Ximing Lu, Yejin Choi, Youngjae Yu COLM, 2025 We systematically detect ambiguous & mislabeled examples in fact-verification benchmarks and introduce Clearfacts and Grayfacts, along with a SOTA 8B fact verifer and insights on building better fact verifiers. arxiv / code / bibtex |
|
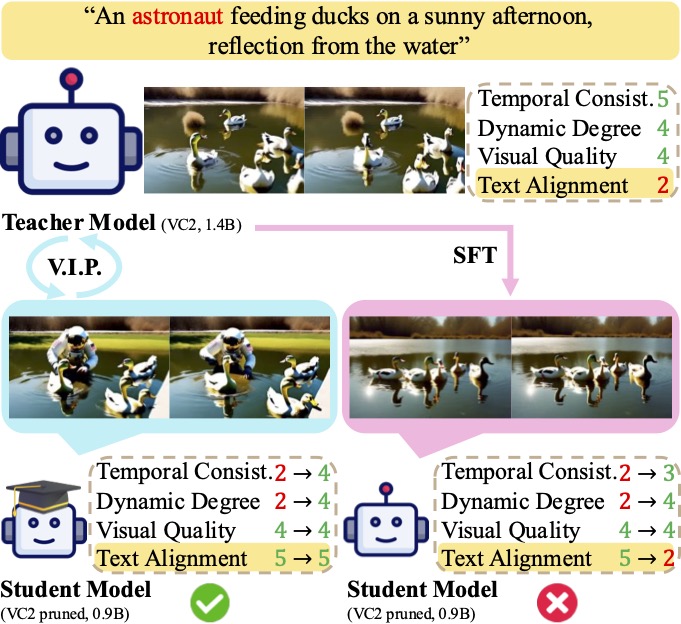
V.I.P. : Iterative Online Preference Distillation for Efficient Video Diffusion ModelsJisoo Kim, Wooseok Seo, Junwan Kim, Seungho Park, Sooyeon Park, Youngjae Yu ICCV, 2025 We integrate DPO and SFT loss for distillation to build an efficient video diffusion model, with an automatic pair curation pipeline and outperform the teacher only with the synthetic data generated from the teacher itself. arxiv / bibtex |
|
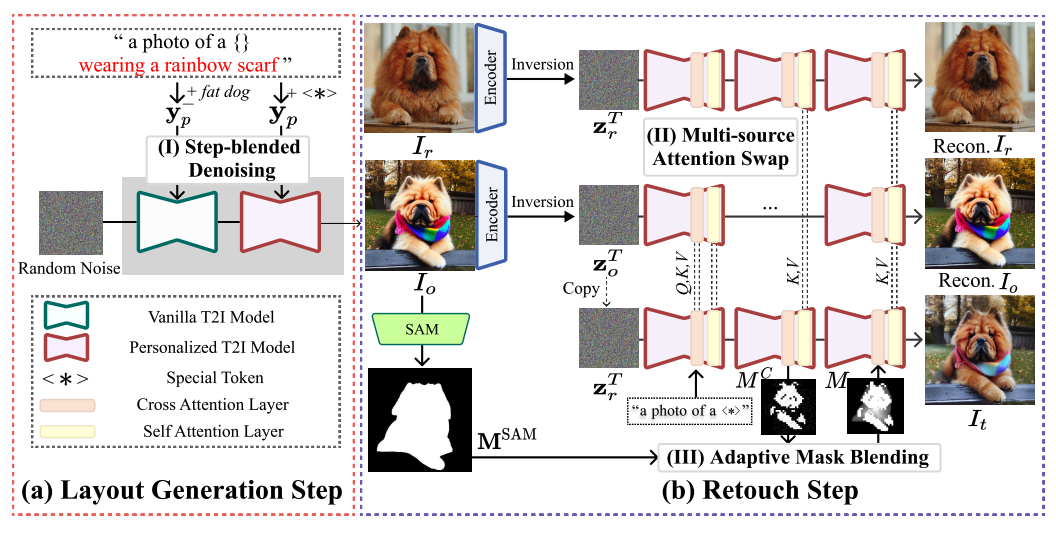
Layout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image GenerationKangyeol Kim*, Wooseok Seo*, Sehyun Nam, Bodam Kim, Suhyeon Jeong, Wonwoo Cho, Jaegul Choo, Youngjae Yu Under Review, 2024 We use a two-stage approach for personalized T2I generation, to first draw the context with step-blended denoising and enhance the context with multi-source attention swapping. arxiv / bibtex |
Academic Services |
Reviewer
|
|
Design and source code from Jon Barron |